
In this article, we will delve into the application of Long Short-Term Memory (LSTM) Autoencoders for predictive maintenance in a stone crushing plant. If you’re new to this topic, I recommend reviewing my previous articles where I’ve discussed the working principles of a stone crushing plant, the operational challenges it faces, and the necessary sensors for applying machine learning algorithms. This will provide a better context for the information presented here.
Our primary focus will be on LSTM Autoencoders, a type of recurrent neural network that is particularly effective at learning from time series data. This makes them an ideal choice for analyzing sensor data for anomaly detection and predictive maintenance in the context of a stone crushing plant.
While we will touch upon the use of a plant dashboard for real-time monitoring, the main emphasis will be on the application and benefits of LSTM Autoencoders in this setting.
Why make a Smart Plant Dashboard?
Using a sensor-informed smart dashboard to monitor an industrial plant offers several advantages:
Real-Time Monitoring: Sensors provide real-time data on various parameters of the plant’s operations. This allows for immediate detection of any anomalies or deviations from the norm.
Efficiency: A smart dashboard provides a centralized view of all operational aspects of the plant. This makes it easier to identify areas where efficiency can be improved.
Safety: Continuous monitoring of the plant’s operations can help in identifying potential safety hazards. This can contribute to creating a safer working environment.
Human Analysis: The data presented on the dashboard can be analyzed by plant operators and managers. This human analysis can provide insights that automated systems might miss, and allows for more informed decision-making.

In Li z et. al. They use MEM sensors to take vibration readings from an electronic component insertion machine. This is then passed to an edge layer and then relayed and stored in a centralized cloud service. In this way, data can be collected, stored, and eventually displayed for monitoring.

This is an example of a plant dashboard that is updated in real-time. All the readings are displayed in one place in a way where it is easy to compare readings between different machines. There is also some time series data, using which we can get an idea of the progression of the readings.
Predictive maintenance
The data collected from the plant can indeed be leveraged for predictive maintenance. However, it’s crucial to note that this data will likely be highly imbalanced due to the infrequency of machine failures. This imbalance necessitates the use of unsupervised machine learning methods, as we will predominantly be dealing with unlabeled data.
There are various methodologies available for detecting anomalies in machine function. Until now, our perspective has been plant-centric, considering the entire plant when addressing the issue. However, for predictive maintenance, it would be beneficial to shift our focus to individual machines. This is because each machine operates on a largely independent maintenance schedule.
In essence, a more granular, machine-level approach could enhance the effectiveness of our predictive maintenance efforts. Remember, the key to successful predictive maintenance lies in the quality of the data collected and the appropriateness of the analytical methods employed.
Cone crusher
The Cone crusher is the most critical machine in the plant. This machine requires regular maintenance, and it’s important to note that its spare parts can be quite costly. We have previously discussed the working principle of the cone crusher and the various components involved. It’s essential to understand these aspects to effectively manage and maintain the machine.
Wear profile estimation for wear parts

The longevity of the cone crusher liner is a crucial aspect of a plant’s operation and profitability. Typically, our cone crusher liner is replaced every 30,000 tons. However, this frequency can vary depending on the type of material being crushed. For instance, when crushing limestone, the replacement may be required 4-5 times more frequently.
The Remaining Useful Life (RUL) of this component is of paramount importance. Given that it’s a wear part, monitoring the rate of wear is essential to detect any deviations from the normal functioning of the cone crusher.
To measure the wear of the cone mantel and liner, we don’t necessarily need complex algorithms. The wear of the liner will naturally increase as the cone crusher continues to be used for production. The key is to analyze the rate of this wear and establish thresholds to identify any outlier values. This simple yet effective approach ensures the optimal functioning and longevity of the cone crusher.
Data collection
Firstly, we would measure the closed-side setting (CSS) and the open-side setting (OSS) for the cone mantel and liner. These settings indicate the distance between the mantle and liner at the bottom and the top of the cone crusher, respectively. We would also measure the position of the main shaft using the hydraulic system. Secondly, since the OSS and CSS measurement can only be done before and after a session, we would not be able to have real-time wear measurements.
Establish baselines:
We first need to measure the baseline, that is, the case where there is 0% wear. We will do this by doing the following when we install a new cone mantel and liner set.
Raise the main shaft to its highest and measure the CSS. This is CSS with 0% wear.
Use the cone mantel and liner with the needed CSS required.
As we keep using the worn parts, after a session, repeat step 1. Raise the main shaft to it’s highest and measure the CSS.
There will come a point where we will be using the cone mantel and liner with main shaft at it’s highest. As we keep using the machine, we will no longer be able to achieve the required CSS even wit the main shaft at it’s highest. At this point, we can call this 100% wear.
Logging Time: Given that the CSS measurement can only be conducted after a session, our readings will be captured in discrete time steps.
Production Logging: An alternative approach could be to log the number of tons produced instead of the number of production hours. This is because we tend to have more empirical data on the former
Data processing
To analyze the wear of the cone mantel and liner, we need to process the data we have collected from the readings. Instead of the absolute wear values at different time points, we are more interested in the rate of change of the wear over time.
Calculate rate of change: We can estimate the rate of change by taking the difference between two consecutive wear readings and dividing it by the time interval between them. We can use either the number of hours or the number of tons produced as the time unit.
Account for irregular time steps: Since the wear readings are not taken at regular intervals, we need to adjust the rate of change calculation accordingly. The time interval should reflect the actual duration between two readings.

Plotting

This plot shows the expected wear pattern of the mantle and liner. Initially, there is a high wear rate due to the break-in period, followed by a steady wear rate as the components operate normally. Finally, as the mantle and liner approach failure, the wear rate increases rapidly.
Predicting the time for replacement and repair
Once we have the time series data of the wear and the rate of wear measurements, we can employ a standard Long Short-Term Memory (LSTM) model to predict when the wear will exceed the 100% mark. The inputs to this model would be the wear percentage and the rate of change measured after every session, while the output would be the number of hours of production. This approach allows us to proactively schedule maintenance and replacement, thereby enhancing the efficiency and longevity of the cone crusher.


The process begins with an LSTM (Long Short-Term Memory) cell, which is depicted on the left.
The input data is then passed through the LSTM model, which consists of multiple LSTM cells. These cells are represented as ‘A’.
At each step, the model estimates the time of repair.
As more data is processed, these estimates are continually updated, leading to increasingly accurate predictions over time.

In this equation:
Tons Left: represents the predicted number of tons left for the cone mantel and liner.
LSTM(X): represents the LSTM (Long Short-Term Memory) model as a function that takes an input X.
Current Cumulative Tons Produced: represents the current cumulative tons produced.
Anomaly detection using autoencoders The wear pattern of cone crusher parts can indeed vary based on several factors. For instance, setting the Closed Side Setting (CSS) too low can accelerate and possibly uneven the wear rate. Other potential causes for irregular wear patterns could be a fault in the motor or misalignment of the main shaft, among others. It’s crucial to detect these anomalies early to prevent further damage to the machine.
To this end, anomaly detection techniques in machine learning and deep learning can be employed. These techniques can help identify wear patterns that deviate from the norm, indicating potential issues with the machine’s operation. By leveraging these advanced methods, we can ensure the health and longevity of the machine, thereby enhancing its efficiency and productivity.
The image depicts a cone mantel that has worn unevenly, with more wear visible at the top and bottom, while the middle part exhibits less wear. This uneven wear pattern can lead to inefficient usage of the mantel, as it does not fully utilize the lifespan of the part. It’s crucial to monitor and address such wear patterns to ensure optimal performance and longevity of the cone crusher.
LSTM Autoencoders
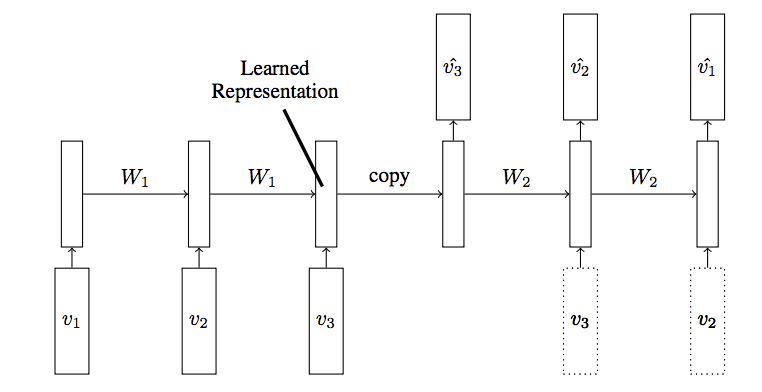
The paragraph describes an LSTM (Long Short-Term Memory) autoencoder, which is a type of recurrent neural network used for sequence data. In this model:
W1 represents the encoder, which learns a representation of the sequence in a latent space.
W2 represents the decoder, which reconstructs the data one by one.
v1, v2, v3 are the data points in the input sequence.
The encoder takes the input sequence and compresses it into a latent space representation. This representation is then passed to the decoder, which reconstructs the data sequentially. The first output should be v3, the second output should be v2, and so on. This process allows the model to capture the temporal dependencies in the data and reconstruct the sequence accurately. Data
As previously discussed, the data collection process will yield wear and rate of change of wear at irregular intervals. For instance, sometimes the machine may run for an hour, and sometimes for six hours. To create a consistent dataset, we can distribute the wear evenly across the hours of operation.
For example, if the cone crusher operates for six hours and incurs 6% wear, we can assume that the wear is distributed linearly across those six hours, attributing 1% wear to each hour.
We believe a window size of 64 hours is reasonable, as this is the maximum duration the cone crusher can operate over a four-day period. However, this window size could be adjusted if necessary.
Therefore, the input size would be (64,1), with these 64 values fed sequentially to the encoder. The output sequence would also be (64,1). As this is a reconstruction, both of these vectors would be identical. This approach allows us to create a regularized dataset from irregular time intervals, enhancing the effectiveness of our predictive model.
Training Process Loss function: The loss function will be MSE(mean squared error) between the input and the output data. This can also be called reconstruction error.

‘Yi’ represents the output of the decoder for the given time steps.
‘y^’ stands for the true value.
The difference between these values is squared, summed over all examples in the batch, and then divided by the number of examples. This forms the basis of the mean squared error used as the reconstruction loss.
Unlike typical LSTM applications for next-word generation, where the output sequence is shifted one timestep to the right, our goal here is to reconstruct the sequence.

The two graphs illustrate the performance of the model under normal and abnormal conditions for the cone crusher. The red line represents the actual data, while the blue line represents the predicted data.
Under normal conditions, the model’s predictions closely align with the actual data, indicating the healthy functioning of the cone crusher. However, under abnormal conditions, which could suggest a potential fault in the machine, the model’s predictions deviate significantly from the actual data. This is expected and desirable, as the model isn’t trained on such sequences and therefore, the loss is higher.
Loss on normal test data


As you can see there is a discrepancy in the loss when testing on normal data and anomaly data. The loss for the normal data is much less, hovering around 0.02, but for the anomaly data, the loss is around 0.9.
This discrepancy in the loss under abnormal conditions is precisely what we leverage for anomaly detection. A higher loss indicates a deviation from the normal operational patterns, thus signaling a potential anomaly or fault in the machine. This approach allows us to proactively identify issues and perform necessary maintenance or repairs.

Setting a threshold for anomaly detection is crucial. If the loss exceeds this threshold, we classify it as an anomaly. Conversely, if the loss is below the threshold, we classify it as normal data.
One approach could be to prioritize capturing all anomalies, even at the risk of occasionally misclassifying normal data as anomalous. This strategy prioritizes the detection of potential faults, ensuring the efficient operation and maintenance of the machine. However, it’s important to strike a balance to avoid excessive false positives, which could lead to unnecessary inspections and interventions.
Conclusion
In this blog post, we explored how to use sensor data from a stone crushing plant to optimize its performance. We applied machine learning and deep learning techniques to predict the optimal time to replace the wear parts in a cone crusher. We also detected anomalies in the wear profiles of the parts over time, which can help us identify potential faults and damages in the machine. In the next part, we will examine how to collect and analyze other types of data from the machine that can indicate different kinds of problems. This way, we can improve the efficiency and reliability of the stone crushing plant.
Comentários