In part 2 of this two-part blog series, we have presented a method for predictive maintenance on machines in a cone-crushing plant using machine learning and deep learning techniques. In part 1, we showed how we can use data from the wear profiles of the cone crusher liners to optimize the time to replace the wear parts and to detect any anomalies in the wear patterns. In part 2, we discussed how we can collect and preprocess other types of data from the cone crusher, such as temperature, pressure, and vibration, and apply similar models to detect anomalies in the function of the plant. Our method can help improve the efficiency, reliability, and safety of the cone-crushing plant, as well as reduce operational costs and environmental impacts.
Why collect more data?
Deep learning models are known for their need for large amounts of data. Without sufficient data, these models tend to overfit the training data and do not generalize well in production. Moreover, the data must be informative enough for the specific task at hand. For instance, if we want to build a model to predict housing prices, and our data only includes the total square footage and the number of bathrooms, our model will not perform well on real data without additional features like location and age of the house.
Detecting different and varied Faults and Anomalies
in the context of a cone crusher, different faults and anomalies will manifest in different parts of the machine. For example, a misalignment in the main shaft will alter the wear profile of the cone mantle, while a suboptimal lubrication system will result in higher oil temperature and power draw due to increased friction.
Real-Time Anomaly Detection for Predictive Maintenance
Real-time data collection and processing can significantly improve the efficiency of predictive maintenance. Measurements such as the closed side setting (CSS) can only be taken when the machine is not running. However, other types of data like vibration and temperature can be collected in real-time. Therefore, a model that can process this real-time data will allow us to detect anomalies during production and prevent catastrophic faults. This highlights the importance of collecting and utilizing a diverse range of data for predictive maintenance.
Sensors for cone crusher

To monitor the performance of the cone crusher in real time, we also need to install various sensors that can collect and transmit data about the machine’s condition. The sensors relevant to the cone crusher are:
Vibration sensors
Acoustic sensors
Cameras
lidar sensors
Oil flow sensors
Oil temperature sensors
Power usage sensors
Data collection
From the readings from these sensors, we will be collecting data that will give us an insight into the functioning of the cone crusher. We will discuss how each sensor might help build the feature vector for the representation of the state of the machine.
Vibration sensors: These will monitor the frequency pattern of the machine and detect any changes that indicate a fault or a developing fault.
Acoustic sensors: These will record the sound of the motor and other parts of the machine and help us identify any abnormal noises that signal a problem.
Cameras: These will capture images of the output material and analyze its shape and cubicity, which are measures of the quality and efficiency of the crushing process.
Oil flow sensors: These will ensure that the lubrication system is working properly and that the oil is circulating smoothly and sufficiently to prevent friction and damage to the machine parts.
Oil temperature sensors: These will measure the temperature of the oil and alert us if it goes above or below the optimal range, which could affect the viscosity and performance of the lubrication system.
Power usage sensors: These will track the amount of electricity that the machine consumes and help us identify any spikes or drops that could indicate a fault or a potential failure.
Lidar sensors: These sensors will be used to measure the closed side setting (CSS) of the cone crusher. Since these readings can only be taken when the machine is not running, we will have to make an assumption that the cone mantle wears linearly during a production session. This will allow us to extrapolate and have a CSS reading for each time step.
Data preprocessing
Data preprocessing is an important step in predictive maintenance, as it can improve the quality and reliability of the data collected from different sensors. In this section, we will describe how we preprocess the data from each sensor individually, and what features we extract from them. We will use a 15-minute window for each sensor, as it is a common practice in predictive maintenance.
vibration sensors

Given the outdoor setting of our machine monitoring, the data from vibration sensors is likely to contain a significant amount of noise. To address this, we can apply various preprocessing techniques:
Denoising: We can utilize filtering and smoothing methods to eliminate most of the noise from vibration signals. Numerous open-source Python libraries offer implementations of these methods.
Find condition indicators: Once we have clean data, the next step is to extract condition indicators from the raw data. These indicators can be derived in several ways:
Signal-based Indicators: Simple statistical measures like mean and standard deviation over the period can serve as basic indicators.
Complex Signal Analysis: More sophisticated analysis can involve examining the frequency of the peak magnitude in a signal spectrum or a statistical moment describing changes in the spectrum over time.
Model-based Analysis: This involves estimating a state space model using the data and then analyzing the maximum eigenvalue.
Hybrid Approaches: These approaches combine both model-based and signal-based methods. For instance, we can use the signal to estimate a dynamic model, simulate the dynamic model to compute a residual signal, and then perform statistical analysis on the residual.
Acoustic sensors:

Acoustic sensors, like vibration sensors, are likely to capture a significant amount of noise due to the outdoor environment of our machine monitoring. However, traditional denoising methods may not be effective here as they might not be able to distinguish the useful sound from the noise.
In deep learning, mel spectrograms are commonly used as representations of sound for input to models. A mel spectrogram applies a frequency-domain filter bank to time-windowed audio signals. These spectrograms can then be processed with convolutional layers in our model, providing a robust method for handling the noisy data from acoustic sensors.
Cameras for cubicity/sphericity measurement:
Using cameras for cubicity measurement presents a complex challenge in our input vector. While there are third-party software solutions available for estimating the shape of our output feed, these require detailed study to ensure their effectiveness. Yang, J., & Chen, S. (2016) proposed some promising methods that might apply to our situation.
However, if these methods prove insufficient, we will develop a novel deep computer vision-based system to estimate the cubicity of the three different products. This system would provide three floating-point values indicating the percentage of cubic material in each product. Given that cubicity doesn’t change rapidly, we can afford to take this reading once per window. This approach allows us to balance the need for accurate data with the practicalities of data collection.

Oil flow and oil temperature: The measurements from oil flow and temperature sensors are straightforward yet crucial. We would simply need to take the mean of the readings over each time window. These measurements provide vital information about the lubrication and cooling status of the machine.
Power usage sensors: Power usage sensors present a different challenge. The power draw of the cone crusher is highly volatile, depending on factors such as the input feed size and the type of material. Therefore, we need to clean and smooth the data to prepare it for analysis. This process, along with finding condition indicators, will be particularly useful here, given the volatility similar to that of vibration frequencies.
Feature vector

In the diagram above, we show how we can construct the feature vector using the readings from the sensors. The Convolutional Neural Network (CNN) models included in our approach represent the preprocessing required for the mel spectrograms and the images received from the cameras for cubicity measurements. These models will be pre-trained to output appropriate latent representations as needed. This process forms the basis of our feature construction, enabling us to capture and utilize the most relevant information from our sensor data.
Model architecture
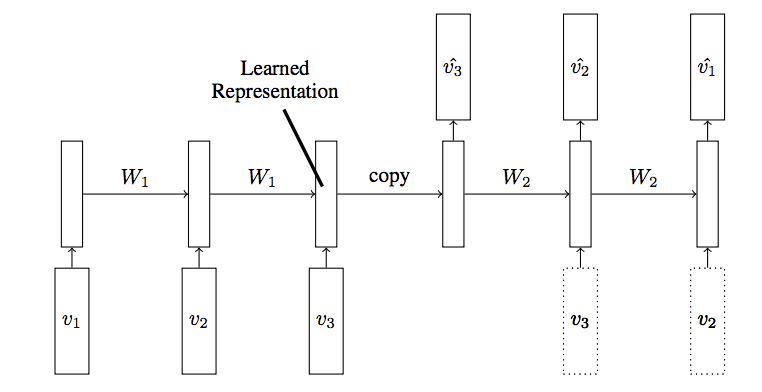
Our model architecture for the wear parts of the cone crusher will employ an autoencoder with Long Short-Term Memory (LSTM) layers for encoding and decoding the input data. The primary objective of this model is to reconstruct the feature vector that represents the healthy functioning of the cone crusher. It’s important to note that the specific parameters of the model, such as the number of LSTM cells, the number of nodes in the fully connected layers, and the output shape, are only representative at this stage. We anticipate that some experimentation will be necessary to determine the optimal model architecture.

An LSTM autoencoder is a type of recurrent neural network used for sequence-to-sequence problems. It consists of two main components: an encoder and a decoder.
Encoder: The encoder processes the input sequence and compresses it into a fixed-length vector representation, also known as the “context vector” or “latent vector”. This is done through several LSTM layers. In the diagram, the encoder consists of two LSTM layers with 16 and 96 units respectively.
Decoder: The decoder takes the context vector and generates the output sequence. It also consists of several LSTM layers. In the diagram, the decoder has two LSTM layers with 96 and 16 units respectively.
The goal of the LSTM autoencoder is to reconstruct the input sequence as accurately as possible. This is achieved by minimizing the difference between the input sequence and the output sequence during training. The LSTM autoencoder learns to capture the most important features of the input sequence in the context vector, which can be used for various tasks such as anomaly detection, dimensionality reduction, and time series forecasting.
Model Training:

Mean Squared Error (MSE): This is calculated by taking the difference between the predicted output (ŷ) and the actual output (y) for each data point (i), squaring it, and then averaging these squared differences over all data points (n).
Our loss function will be the Mean Squared Error between the predicted value and the true value. Note the true value in this case will be just the input sequence since that's what the autoencoder has to reconstruct.
Optimization:
During the training process, the model tries to minimize this MSE loss. This is done using an optimization algorithm, typically gradient descent, which iteratively adjusts the model’s parameters to reduce the MSE.
note: In the context of an autoencoder, the MSE is often referred to as the “reconstruction loss”. This is because the autoencoder tries to reconstruct the input data from the encoded representation, and the MSE measures how well the reconstructed data matches the original input data.
Model evaluation:
Once the model has been sufficiently trained, which is determined by observing that the loss value no longer decreases despite further training, we can evaluate its performance on the test set. This is data that the model has not been trained on, providing a true test of its generalization ability.
loss on normal test data

For well-trained models, the reconstruction loss on normal test data is typically low. For instance, in most examples here in the test set, the reconstruction loss is center around a value like 0.02.

The loss plot on the data for anomalies will look a little different from the data that we already trained on, the distribution will be centered around a significantly higher reconstruction loss since the autoencoder hasn’t been trained on this data.However, when the model encounters anomalous data, which it hasn’t been trained on, the distribution of the reconstruction loss will be different. It will likely be centered around a significantly higher value, reflecting the model’s struggle to accurately reconstruct these unfamiliar data points.

By plotting the reconstruction loss for normal and anomalous data together, we can clearly see the difference between them. This allows us to establish a threshold for classification between normal data and anomalies, enhancing our model’s ability to detect unusual patterns in the data.
Anomaly detection during production

During production, we can utilize this model to detect any anomalies in the functioning of the cone crusher. This is achieved by logging all sensor data for the same time frame that the model was trained on and feeding this data into the autoencoder.
We previously established a threshold during the evaluation phase to categorize data as normal or anomalous. If the reconstruction loss exceeds this threshold, we tag the data point as an anomaly. Subsequent steps, such as triggering an alarm or sending a notification, can then be taken based on this anomaly detection.
It’s also crucial to continually log sensor data and periodically retrain our pre-existing autoencoder. This ongoing training process helps to improve the model’s accuracy over time, ensuring it remains effective as the machine’s operating conditions change.
Conclusion
In this post, we discussed how we use sensor data to detect anomalies in a cone crusher in a stone-crushing plant. We looked at the different sensors that we need to collect the data and then discussed how to preprocess them to construct a feature vector that can be used as input to an LSTM autoencoder. We saw how we can train the model and how to come up with a threshold to categorize an anomaly from the normal functioning of the cone crusher.